理想的なワークフロー
図2でお話ししたかったのは、現状でもWindows ベースでDTP システムを組んでいて十分問題ない、遜色ない状況までになってきました。もう一息ですよというようなところをご理解いただきたかったのです。もう一息ですよというのは、さっきちょっと私は、これが出てくればバンバンザイですねみたいな話をしていたOpenTypeですが、まだ多くで使われているものの全部がフォント出ているわけではないものですから、今、即変えていただくわけにはいかないかもしれないのですが、こういうものは順次、こっちのほうに変換してくると、こういう形の環境というのは比較的簡単に整えられます。そうすると、比較的柔軟性はあります。なにせWindows
マシンというのは安いですから。Macintosh というのはまだ高いでしょう。それに比べたらWindows は安い。こんなマシンでも、ちょっとした制作くらいでしたらWindows
でできます。こんなのだったら数万円で買える。この間、Windows XPがほしいのでとりあえずと思って買ったマシンが3万9,800 円で、1ギガヘルツで、ディスクが30ギガとかついている。そんなものでも仕事はできてしまう。さっきお話ししたOpenTypeを使った広報誌というのはそのマシンでつくっています。モニターなんていくらでもころがっていますから、そういうことを考えると非常に設備費用が安く済んでしまう環境ができますよということをお話ししたいわけです。
そして理想的なワークフローという形になるんですけれども。さっき一部お話ししてしまった部分がありますが、現在、フォーマットやアプリケーションが複雑になっているのは、やはりMacintosh
DTP とWindowsのデータフォーマットがごちゃごちゃしているということだと思います。これらは、Windowsベースのシステムで集約されていることで、統合に向かうと考えられると思います。
また、新たなフォーマットとして、XML が広まることで考えられるため、このようなデータに対応していくことも重要です。
このようなことでちょっと止めておいて、図3を見ます。
| 図3 |
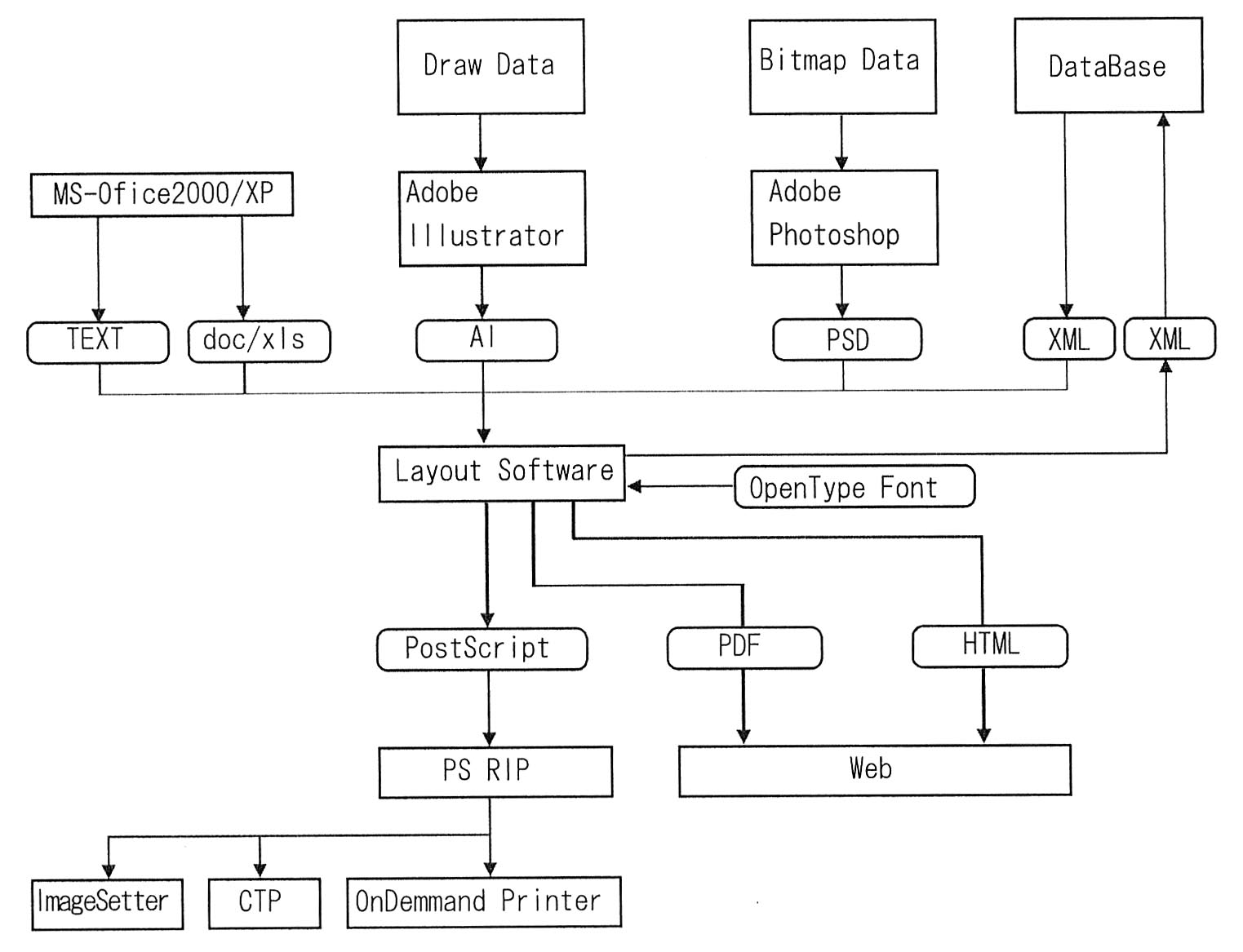
|
XMLについては、このあとでちょっと話をしたいと思います。XMLというのはここに存在しているのですが、ちょっとこれを外しておいて、こうです。そういうふうに考えると、これでいいんじゃないですか、と。
Officeから出てきたデータは、ネイティブデータ、それぞれAdobe Illustrator、AI。Draw DataはIllustratorで吸収して、その上で印刷上の処理をする。印刷上の処理というのはCMYK変換とかノセの設定、解像の設定というのは、別にWindowsでもMacintoshでも関係なしにどうしても印刷適性で考える上で必要なことですから、それはやらなければいけない。
Photoshopに関しても同様です。通常のBitmap Data、これらに関しては通常はRGBでできていますから、それは、きちんとしたCMYKデータ、あるいはそれ以外の色を使うのでしたら、しかるべき特色の処理をするというようなことが必要です。
それらは、いままでのようなデータ交換の中間フォーマットに落とすのではなくて、標準フォーマットで落としたものをLayout
Software で集約して、OpenType Fontを使って組んでいく。それが印刷物になったり、PDFになったり、HTMLになったり、他のデータになったりする。そういうような形の展開がもう今でもできるのではないですか。
さっきは、ここ(Layout Software) にInDesignソフトの名前を出していましたが、別にInDesignである必要はないと思います。ただ、こういうもの(AI、PSD)を受け入れていくと、Adobeぐらいのものになってしまうのかなと思いますが、別のものであったとしても別に構いません。
こういう形で流れていくのが、一つは理想に近いだろうと思います。
エンジニアリング・ドキュメント作成システム事例
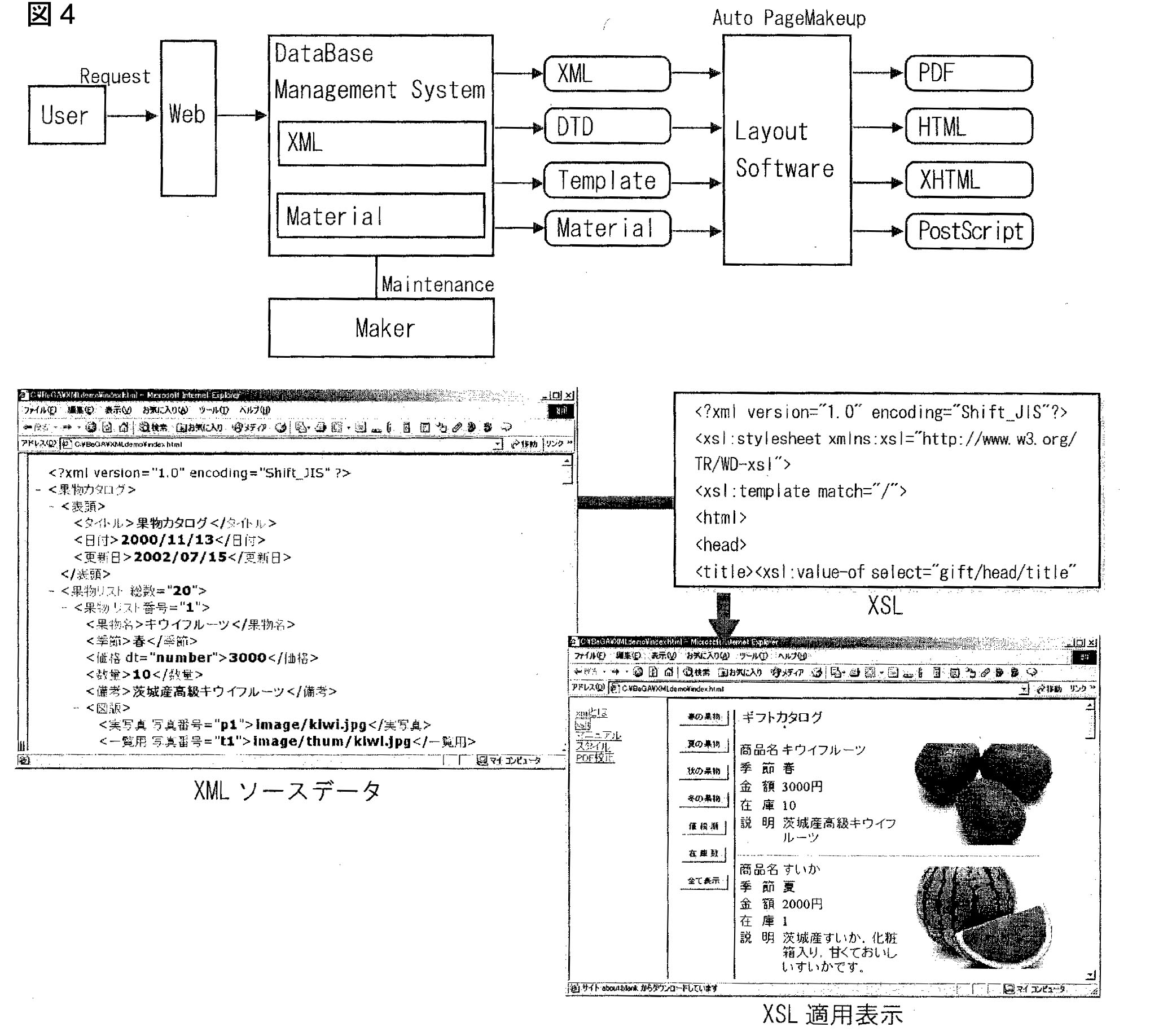
頭のほうでちょっとXMLデータの話もしてしまったのですが、次の図4下のほうにXML
の話がある。ちょっとこのへん図を出しているだけでわかりにくい部分があると思いますので、こちらの説明を先にしてしまおうかと考えております。要するに印刷物用のデータのなかにいきなりこういうデータが入ってくると、ちょっとよくわからない部分があると思いますので、ちょっとこんなふうなもの図4「XML
ソースデータ」)を見ていただきたいと思います。
XMLについての説明をし、その効果を説明した上で、では、それをどういうふうに利用するか、それからそれをどういうふうに商売に結びつけていくかという話もしなければいけないだろうと思います。
まず、「XML」という用語を最近聞いたりすると思いますが、これは「Extensiple
Makeup Language」の略です。それだけいってもよくわからないと思うのですが、要するに、こういうもの(図4「XML ソースデータ」)です。大した話ではない。
普通のデータと何が違うかという話になります。ちょうどいいものがあまりないのですが、要するに、普通の文字データとか普通のデータはどういうものかと考えていただくだけでもいいのかもしれません。何でもいいので、適当なデータを置きます。
これは何もコーディングもされていない普通の文字データです。例えば、うちの会社の概要がどうのこうのとかあります。普通の文字データというのは、こんなふうになっています(「会社名:株式会社ビィーガ 代表者:白旗」~)。この内容を処理していくとき、人間がみれば、これは「社名」「代表者名」。これは箇条書きで何か入れておいて、ここは「業務内容」コロンで何とかとついているなということがわかると思います。
コンピューターにこれらの意味内容を教えて区別させるための工夫が「マークアップ」という言い方になります。マークアップというのは、皆さん方も校正でやります。例えば何か誤植があったら、線を引いて別の文字、校正記号を入れたりします。文章に対して何かの書き入れをする。そのことをマークアップといいます。だから文章に書き入れをすることをマークアップといいます。そういうふうな規格があります。そう考えていただきたいと思います。
ですから、通常の文章ですと、これは人間が処理する以外に何の処理のしようがない。それに対してXMLというのは、その意味内容とするものを文字として定義ができます。だから、普通はこんなもの(図4XMLソースデータ <タイトル> <日付> <更新日>等)がなかったら、「果物カタログ」「2000/11/13」「2000/07/15」と書いてあるだけですと、人間がそれを処理しなければいけない。現実に今のDTPシステムは、人間がそれぞれの文字を見て、ああ、これはゴチックだ、これは何にしよう、という処理の判断しています。そうではない。ある特定のルールにしたがって、それぞれの文字データ、だからリストが多くなりますが、その意味内容を表記しましょう、表記のしかたのルールをつくりましょう、というものです。
例えばこの「果物カタログ」という一つの括りに対して、「タイトル」「日付」「更新日」、小なり大なりの括弧で入れて、これをスラッシュで入れると、タイトルが始まり、タイトル終わり。だからタイトルというのは「果物カタログ」という文字ですよというふうに決めた規格があります。いってみれば、これがXMLというものです。大して複雑な話ではない。ですから、データの中身に意味を持たせる規格、そのように考えてしまえばいいです。まず一つこう考えてください。
そのメリットというのは、簡単です。例えばこういうデータになっていれば、「<果物名>」と書いてあります。それが「</果物名>」となると、この「果物リスト番号=“1”」の果物名は「キウイフルーツ」なのです。だとすれば、こういう文章のなかに入っているもののなかから果物名だけをリストアップしなさいといったら、簡単にできるわけです。
でも、普通の文章だったら、このなかで人名が含まれているものをリストアップしようというのは無理です。それをするための技術の一つがXMLです。本来は、このXMLというのは、よくいわれたのは、「全文書データベース」という言い方をされています。例えば一冊本があります。そのなかのものを全部データベース化するためにはどうしたらいいか。データベースを打つのは簡単です。文字データを打って、そのテキストデータをデータベースのどこかに放り込んでおけばいいのです。それはそれで確かにデータベースはあるのですが、では、その本のなかの要約だけほしいというときにはどうにもならないです。著者だけほしいというときにどうにもならない。著者がどれだかコンピューターはわからない。人名を引っ張ってくることはできるのですが、そうしたら、小説のなかに入っている人名を全部引っ張ってくる。著者かどうかわからない。
そういうことで考えれば、一つの文書、本当は全文書といっているのは、世界じゅうにあるそういう文献データを、画一的に扱うことができるようにしたいというのが基本です。そのためにでき上がってきたのが、こういうXMLという規約です。
その前のSGMLという規格もあったのですが、それはちょっとつくりにくいものですから、なかなか普及しませんでした。例えばXMLなら、「タイトル」とか「果物名」、この名前を自由につけられます、SGMだと自由につけられなかったりします。自由につけられないのだと、ある程度、標準化ができる。自由につけられないというのは、どこか決まっているわけですから。決まっているものだけを使っていきましょうということだと、ある程度規格化はできるのですが、やはり自由度がありませんでした。
例えば、これはうちのホームページですが、このなかのソースを引っ張ってもらうと、これはそのなかに入っているHTMLのそのものなのです。HTMLも、MLとついていますから、マーカアップランゲージなので、基本的には同じような出し方をしています。HTMLもXMLも似たようなものです。
その場合には、例えばタイトルは、括弧、小なり大なりで、「<title >」「</title>」と、ある程度、XMLでは決まっている。他の文字を書くとタイトルとしては認識されません。そういう規格が決まっているのです。だから、逆に、範囲が狭い分、ホームページのデータは使いやすい。規格が決められて、これだけしか使ってはいけませんよといえば、その分だけしか使いませんから、つくりやすいということがあります。そのかわり拡張性はない。ちょっと面倒くさいことをやろうとか、こういうタグといわれるものがもう一つ二つほしいといっても、それは認められない。そういうものですと、どうしても柔軟性に欠けるということがあるものですから、最近では、こういうXMLというデータになっています。
XMLというのは、何となくデータの内容に意味を持たせるために、このような小なり大なりの括弧でくくって意味合いをつけるものだということはおわかりいただければいい。とはいっても、皆さま方もおわかりだと思いますが、文字データというのは、これはテキストデータですが、このままではやはり印刷物にならないわけです。こういうものはLayout
Softwareに読み込んで、ある特定のポイントを与えたりサイズを与えたり、場合によって文字化を設定したり、インデントを設定したり、タブを設定したりして、体裁を設定していく。そして初めてテキストデータが売り物になる印刷データになるわけです。このように、体裁が必要です。
XMLのメリットは、ここにあるデータ( 図4の「XML ソースデータ」)
は一つです。ただそれに対してスタイルを別に与えることができます。スタイルというのは、例えばこれはある特別のスタイルを与えたものです。Xsltと書いています。xml
stylesheetを使うと、例えばこのデータはこのような形(図4「XSL適用表示」) に簡単に変換ができます。
これは、要するにstylesheetというのは、ある一つの大きさがこれくらい(画面半分位)ですよ、表層にどういう文字が入って、それぞれの穴のあいたところには、先ほどの括弧でくくったどのデータを持ってきますよ、という定義をしているだけの話です。
このような形にしますと、例えば「夏の果物」「春の果物」などは、当然そのなかのデータから引っ張ればいい。ですから、季節があるでしょう。そして項目があるでしょう。だったらさっきの「春の果物」は、「季節」というなかに「春」という文字が入っているものだけ引っ張りだして、それを順番に並べればいいわけです。
印刷でこれをやると大変です。「春の果物」を引っ張りだして、並べ替えをして、その分、もう一度スタイルをあてていかないとできないです。でも、stylesheetをあてていくと、例えば、こういうようなことは非常に簡単にできます。「春の果物」「夏の果物」、当然これは先ほどの「季節」という括弧のなかにどういう文字が入っていったかということで引っ張りだしています。
もちろんそれだけではなくて、例えば値段の順番に並べましょうよというときには、さっきの「春の果物」のときとは形式が違います。それから在庫数。これも商品名と在庫数を表示するこういう枠のなか(「XSL
適用表示」)に、ここには何をどういうルールで入れるということが決まってさえいればいいわけです。
これは季節も関係なしに、頭から順番に一番最初のstylesheetを適用しているだけの話なのです。
何をいいたいかといえば、このような形でXMLにしておきますと、そのデータは一つでいいのですが、その見せ方は、先ほど見ていただいているように、一つは「季節ごと」という表示のしかたもレビューし、値段順というやつもできるし、必要であれば写真だけズラッと並べて、そのなかでボタンを押したらこの画面とか、そういう種類のことだって簡単にできます。
何をいっているかというと、データの一つの見せ方は、stylesheetを適用すればどうにでもなるわけです。だから印刷物というのは、ワンソース、ワンユース。一つのデータがあって、それを特定の印刷物にする。そういう話ですが、少なくともこのようなXMLデータと今、style
sheetという話をしていますが、XMLを表示する仕組みというのは、XLstylesheetだけでなくて、他にもいろいろありますが、少なくとも一つのデータがあれば、それをいろいろな形で活用していくことができます。そういうふうなものがXMLだと考えていただければ結構です。
例えばさっきのデータがある。これはあくまでもインターネットのWebサイト上で表示するようなスタイルがあててあるだけではないですか。でも、例えばこのスタイルを適用した形でPDFに変えてしまう。PDFにしてしまえば、PDFを使って面付けして、そこからいわゆるこういうギフトカタログをつくってもいいわけです。もちろん表示用はカラーでつくらなければいけないかもしれないのですが、そういうようなやり方ができる。そういうものがXMLというものです。
何となくピンときますか? ここにある例は、この上に「XSL」と書いてありますが、XSLというのは、正直いって面倒臭いです。でも、それほど難しいものではありません。
こういうふうなものがXMLというものです。覚えておいてください。そして今回の話の上のほうに入りたいと思います。
(図4の上のフロー図参照)XMLというのはどういうものかというのは、ある程度おわかりいただけたかと思います。XMLというのは、要するに文字データです。当然それを最終的にレイアウトするときには、それに対応する、例えばさっきの写真とか図版とかは必要になります。そういうことでいえば、印刷物をつくるためのDTPというもののパーツ構成と何ら違わないでしょう。文字データがあって、図版データがあって、画像データがあって、それをまとめてページをつくる。これはまったく違いがない。そういうふうにご了解いただければいい。
では、ここで「エンジニアリング・ドキュメント作成システム事例」という言い方をしていますが、現在のDTPシステムを敬称し、XMLデータを基本とした自動ページレイアウトFontが多くで進行しています。あまりよく皆さん方は知らないかもしれないのですが、うちも一部かんでいます。かんでいるというか、かなりどっぷり漬かっています。このシステムを利用すると、データベースからデータを取り出し、自動的にページ作成を行なうこともできるようになります。
現在は、1段組程度の簡易なレイアウトを行なうシステムに過ぎないのですが、高度化するにつれて、自動化できる範囲が拡大すると考えられます。
どういうふうなシステムかというと、一般的には、データベースというソフトがあります。SyBase、Informix、DB2、Oracle等、いろいろなデータベースをソフトメーカーさんは当然売っています。そこにソースとなるXMLデータを置いておきます。このデータは、エンジニアリング・ドキュメントと言い方をしていますから、コンピューターのマニュアルとか、コピー機とか、プリンターのマニュアルなどが多い。あのへんのプリンターのマニュアルなどは、だいたい1段組の簡素なレイアウトが多い。文字があって、図版が入っているという程度の話です。印刷で使うような3段、4段当たり前なんていう組み方ではなくて、トップダウンで1段で組んでいるようなものですが、そういうようなデータは、基本的なデータは決まっています。型番とか商品名、パーツカタログのリファレンスリストとか、そこで参照する図版とか、そういう種類のものが入っています。
Materialというのは、XMLに参照される図版の類です。さっきの例でいえば、これ(「XML
ソースデータ」)です。例えばこのページを組むときには、ここに書いてあります。例えば、「実写真番号」はどこにあります。何とかというファイルを読む。「一覧用写真番号」というのは、これです。これはわざと「一覧用写真番号」とか「実写真
写真番号」とかと分けていますが、「実写真」と「一覧用」と、それから印刷用の写真データというのは別に分ける必要があるかと思いますが、そんなふうに設定さえすれば、それぞれの出力用の解像をコントロールすることができます。
だから、画面表示するなら、70dpiくらいのものでもいいけれども、カラープリントで出力するくらいなら300くらい入れておこうとかというような設定で入れておきます。だから印刷物のデータのパーツのデータを入れておきます。
結局、こういうふうなデータを置いておくと、ユーザーは、お客さまから呼ばれて、コピー機の修理かなんかにいったとします。昔は分厚いマニュアルを持っていった。それは必ずしも最新版ではない。そういうような環境のときに、ノートパソコンでも、先にいったら携帯電話になるのかもしれませんが、携帯電話だとマニュアルを見るのに向かないので、やはりノートパソコンくらいですか。上に接続して、データベースを検索して、ある型番の特定のページを指示します。そういう形をとります。
そうすると、このデータベースプログラムから自動的にXMLデータをはき出して、それからTemplate。Templateというのは、さっき言ったようなレイアウトで穴があいたものです。レイアウトのボックスがあって、ところどころに、ここは写真が入るエリア、ここは文字が入るエリアと、区別がついていていいわけですから、そういう種類のものと素材データを入れます。そして自動的にPage
Make upをします。
出来上がったものを、一つはPDFではき出すこともできるでしょう。HTMLにはき出すこともできます。 XHTMLは別にして、PostScriptのデータにして、これを印刷物用に転用することもできます。
そういうふうなものを現状では模索しています。
もうちょっと似たようなものが、これです。これはAdobeさんのセミナーで発表したものですが、「ソリューションワークフロー」なんてなっていますが、現状でも、さっきの図をちょっとグラフィカルに描き直しただけのものです。ワードとか、いろいろなものからXMLというデータを生成することができます。例えば通常使っているのは、イラストとか画像、CAD系のデータ、そういうものは素材のデータベースに入れてしまうことができます。それをWebからリクエストすることで自動でくみ上げて、そしてそれを、一つはWebに出し、それから一つはPDFに出したりすることが当然できるようになります。
このプロジェクト自体は、私が知っているだけでも結構なところで動いています。何をいっているかといえば、さっき例としてお出ししたようなところですと、こういうところです。今は印刷物としてサービスマニュアルを、こんな分厚いものを印刷屋さんにつくっていただいています、という話です。そういう種類のものを自動的につくれないか、ということなのです。
現実にこれはそろそろ初期納品があって、2003年4月くらいになって稼働し始めて、そのあたりになると、また新聞などでお知りになることもあると思いますが、基本的にこういうパターンです。他のところでやっているものも、基本的には細かい仕組みが違うだけです。一般ユーザーは、インターネットの画面を立ち上げるのに、どの型番の、どの番号の、どのパーツ部分のマニュアルがほしいのか、パーツリストがほしいのかを選ぶ。最終的にPDFがほしいのか、HTMLがほしいのか、チェックをしてボタンを押す。しばらく待つと、この処理が自動的に行なわれて、その方のところにPDFなりXMLなりが届く。その画面を見ながら修正をしていく。場合によるとそれだけで終わってしまって、プリントまでいかない可能性があります。そういうことになります。
このようなシステムは、基本的に印刷業の機能を必要とせずに印刷物を生成するシステムになります。現実にこれが稼働しますと、それまでそこのメーカーさんが使っていた印刷物費用は、ほとんどということはないですが、少なくともマニュアル作成費用はゼロになるでしょう。ゼロになることを想定して、何年か分でチャラにできるようにこの予算は組んであるわけです。ですから、ゼロにならなかったらまずいのです。印刷の生成システムがあって、こういうシステムの稼働によってマニュアル印刷物業務が消滅することになります。ですから、そこで仕事がなくなってしまいます。
ただし、そうはいっても、だれかが部品をつくらなければならない。画像の入力をしなければならない。それから、これはデータベースですから、データベースに対するメンテナンスの手間は膨大です。こういう業務を逆に取り込むことは可能です。これは、はっきりいうと、おいしい仕事といえないこともない。なぜかといえば、一番お金を取りにくいのは、レイアウトとか、そのへんではないですか。納期だけ迫られてあまりお金が取りにくいという部分がみえると思います。
だとすると、ある程度お客さまのデータベースのこういう業務を取り込んでしまう。その上で、なおかつそのメンテナンスというようなことをやらなければいけない業務は当然発生しています。最初はお客さまが自分でやるとかいっていましたが、無理です。いままで印刷業界に頼んで図版を起こしてもらったり、画像に入力をしてもらったりしたのに、こういうシステムになったからといって自分たちでやるというのは無理なので、そこのところは、結局のところは、印刷物の制作について、やっていたところに引続きお願いする。
そのかわり、こっち(PageMakeup)がないんだけれども、こっち(
Layout Software)のほうのメンテ関係にかなり入れてくださいよ、というふうな話になっております。ですから、印刷物の発注費用としては、額面上はないのですが、データベースのメンテナンス費用としては、実はもっと金額が取られているという話です。ということであれば、これ(DataBase、Managemnt
System、XML、Material、Maker)を取っていくということは当然できるでしょう。逆にいえば、こういうシステムが増えてくると、今のような形で必ずしも後ろのほうの製版機とか印刷機などの重い設備をもって仕事をしていくということではなく、ある程度、一つはグラフィック制作とか、スキャニングとか、そういうものについてのノウハウを持って仕事をしていくというのは当然可能だと思います。
最終的に組版の技術を左右するのは、Templateのところです。Templateのレベルで、要するに日本語の文章としてよいものかどうか、というようなことが必要とされます。だから、従来からいわれたように、タイトルはどれくらいの文字にしたほうが即威力があるとか、本文はどれくらの文字で何パクくらいで送ったほうが可読性が高いというのは、印刷業界にしかないノウハウなのです。ワープロのほうではないノウハウなのです。そういう種類のものを取り込む必要はあります。
今、うちがこのへんにかんでいるのは、うちがあくまでも印刷系のノウハウを持っているからだけなのです。組版関係が重要だなんていうことは、コンピューター屋さんなんかはほとんどいわない。よくわからないからです。文字なんて並んでいればいいと思っている。そういうわけではないでしょう。そういうことであれば、それは必要になります。
ただし、例えばイラストをつくるだけ、スキャニングするだけをやっていたら、それは競争相手は大きいです。たくさんあります。競争相手が大きいだけだったら、値段競争しかならなくて、値段が下がる方向しかいかないわけです。ここはそうではなくて、ノウハウが必要です。
社内的に、例えばXMLというノウハウがいるでしょう。XMLというノウハウを知るということは、DTD―DTDというのは、Data
Type Difinitionというデータ形式の定義部分です。これもXMLの勉強をすると、勉強しなければいけない類のものです。ですから、こういうものを知っている方、技術者も必要ですし営業さんもいります。営業さんがある程度お客さまと同じベースでお話ができなければ、やはり仕事が取れてこない。技術を知らないなと思ったら仕事は回ってこないです。そういうふうな勉強はいるでしょう。
図版をつくる技術とか、そのへんについてはもう皆さん方すでに持っていらっしゃるし、Templateをつくる際にも、どういうふうな文字組みがいいかというのは、業界のノウハウとしてある程度持っていらっしゃると思います。ですから、むしろ、そこは全然心配しない。そうではない。私、「SGMLというのがいるか」といわれたころには、私は「そんなものはいらない」という立場でした。なぜかといえば、あんな難しいものは一般的に普及するはずないし、そういうものが印刷業のデータとしてくるとは絶対思わないから「いりません」といったのですが、XMLは別です。似たようなものではないかといわれるのですが、普及度が全然違います。だって、この日本のなかで、100社とか、200社とか採用しているようなデータと、1万社とか10万社とか100万社とかが採用するようなデータとは、対応が違って当たり前だと思います。ですので、XMLの世界というのは、印刷業といえども、ある程度自分の知識として持たれる必要はあるだろうと思います。
それと組版とか図版、画像の処理技術を組み合わせていくということで、少なくとも今後、印刷物が減っていくとかなんとかというものには、私は十分対応していけると思います。こういうことであれば、別に紙代の値上がりがどうのこうのと言わなくても済むのではないですか。別に紙などは使わないのですから。そういうことは当然あるだろうと思います。
だから、こちら(図3)に戻るわけです。
そういうことであれば、皆さん方にとってみると、もちろん印刷物もつくるのです。印刷物をつくるためには文字、図形、画像という三つのパーツがなければレイアウトはできないのです。それ以外に、ここでいういわゆるデータベースのものから運用されて描き出されたXML
というものも、印刷用のデータのソースとして存在しうるのです。ですから、それを使って組み上げていくということが当然必要になります。そういうこともこの理想的ななかには入れておいていただく必要がある。
そして申しわけないけれども、現状では、この用途に対応できるソフトウエアというのは、FrameMakerというソフトしかありません。聞いたことがないかもしれませんが、AdobeのFrameMaker
7.0というのは、この間出たばかりです。以前のものより少し安くなって出てきたのです。FrameMaker7を使って今多くのものが動こうとしています。FrameMaker7は、基本的なXMLを入力して、そこから自動的にページを組み上げて、そこからPSなりPFなりに描いていくという機能があります。
それからもう一つ考えておかなければいけないのは、インプットとアウトプットです。なぜかといえば、レイアウトソフトにXMLデータを読み込んで、当然その上で校正を出せば、校正に赤が入らないわけはないわけです。そうすると、その赤は直さなければいけない。赤を直したら、この上で更新されたデータをそのままいままでの印刷だけに持っていくと、修正された情報はここ(
データベース)には更新されないのです。でも、データベースだったら、そこ(Layout Software)で更新された情報は、データベースに戻さなければいけないのです。そういうことでやれば、入力、出力ができなければいけない。出来上がったXMLでこのデータベースをアップデートすると、ここ(Layout
Software)で修正したものがこのデータベースにも反映されて、常に新しい情報がデータベースとして運用されるというフローにならないと、どうしてもいけない。
それで「現状では」なんていう言い方をしたのですが、例えばQuarkXPressでも入力はできます。Avenue.Quarkというソフトを使うと、少なくともXMLの入力だけはできるのだけれども、出来上がったものは、こっち(Layout
Software)に流すだけで、データベースの更新ができないので、結局、人間が手でこれを修正しなければならないという変な話になります。
他のものに関しては、例えばAdobe In Designというのは、確かにXMLの入力もできますし、XMLの出力もできる。それだけみるとよろしいのですが、書式情報がきちんと受け渡せない。書式情報というのは、さっき話に出たDTDというところで当てたりするのですが、ある特定のものを例えば「これは明朝にします」「これは見出しですよ」とか、「見出しだからゴチックにして24級くらいにしますよ」とか、そういうふうな書式をあてることができないですから、InDesignというのは若干不十分な対応になっています。そんなことから、いくつかソフトウエアをここでは切り換えていかなければいけないという現状があります。
ただし、現状ではFrameMakerしかないにしても、よしんばこういうようなデータがある程度増えて、その入力と出力をコントロールしていく必要があるとすれば、そういうビジネスチャンスがたくさんあれば、こういうソフトというのはたくさん増えてくるはずです。そういうふうに考えていただくのであれば、現状では何とかしかない、という言い方をしますが、ここにはどういうものが入ってきてもいい。それで全体として、社内の、いわゆるDTPプラス、XMLも加えた形のパブリッシングシステムみたいなものを構築していくことはできるだろうと思います。またこういうことをやっていくことで、社内的にXMLデータをどういうふうに扱ったらどのように組み上がっていくのかというノウハウは、たぶん蓄積できていくのだろうと思います。
なおかつそういう知識をもってするのであれば、先ほどのお話に入っているような、こういう種類のデータベースを使った形の運用ですが、そういうものについて皆さん方がある程度作業プラス知恵を出した形で取り込んでいくということは、十分可能になってくるだろうと思います。
こういう形がたぶん将来的な理想かもしれないのです。ただ、今のところは、「一段組程度の簡易なレイアウト」といっています。だから、私の今のレジュメみたいなものです。タイトルがあって、文章が一段であって、図版があって、いいところFigureナンバーが入っているとか、そんなものだと思います。そんなものだったら現状はいっています。
これから先それが若干高度化する。高度化する場合でも、ある程度型が決まったものであれば、それはテンプレートを切り換えてしまうことができるわけです。逆に、現段階まだこういうものが始まったばかりです。始まったばかりなので、まだやっているところがほとんどないのです。ですから、うちみたいなところにも仕事がいくらでも流れてくるのですが、できないといって断ってしまっているのです。
そういうようなことで考えるのであれば、こういう部分はもっとたくさん入ってきてもらってもいい。どこでもいいというわけにいかないのです。いわゆるコンピューター屋さんというのはもちろんあります。でも、組版がどうの、フォントがどうのという知識は、印刷屋さんのほうが持っている。では、どっちがいいか。コンピューター屋さんが、その印刷関係の知識を持つのか、印刷屋さんがコンピューター関係の若干高度な知識を持つのか、どっちがいいのか。そういう話です。後者であれば皆さま方の商売になるし、それは今後も広がっていくだろうと思っていますし、そういう形で今、仕事を始め出そうとされている方はかなり多いとご理解いただければいいと思います。
したがって、「多様な印刷データ形式への取り組みとこれからのビジネス展開」というタイトルに戻るのであれば、従来のDTPはMacintoshで中心となって行われてきたものです。それがWindowsになったから、若干データとしてはバラバラしたりしますが、最終的にはやはりOfficeとか、IllustratorとかPhotoshopなどの標準データを取り込んで出力していくという仕組みをつくるのは簡易なことです。フォントはOpenTypeを使っていくということであれば、それはWindowsベースでまったく問題ないし、これからのビジネスということを考えるならば、それプラスさっきお話ししたXMLという技術をちょっと勉強してみてもらえませんでしょうか。そういうふうにすることは、これから行われるであろうデータベースでデータを入手し、そこから自動的に印刷物をつくるとか、PDFをつくるとか、そういうふうな印刷に反対する流れというもののなかに取り組んでいくことだと思います。
そういうことであるとすると、そこのビジネスはとても大きいです。いろいろあります。そういう用途が一つは建設、建築。建設、建築というのは、これから許認可事業になっていきます。昔からもそうですが、昔は、紙の束を持っていって申請していたわけです。そういうことをやりたいかといえば、やりたくない。だから、そういうものがPDFデータの申請になったりする。では、いままでCADでつくったデータをきちんとしたPDFにしなければいけない。そんなノウハウはどこにあるか。うちが専門としている製薬なんかはそうです。もう来年くらいからそういう形になっていますし、総務省のほうでも、かなり大きな部分が印刷物で納品したものは、電子データで納品しなければいけない。それがもっと先にいったら、PDFにしなければいけないですよという縛りになってきたりするでしょう。その場合にいろいろな縛りにかかります。どんな環境でみても、フォントが化けてはいけないとかという仕様がいくらでも出ていますから。そういうノウハウは逆に皆さん方しか持たないとご理解いただければいいと思います。
だから、いままではどちらかというと、技術を使ってつくった印刷物を納品して、お金にしていた部分があるのですが、むしろ使っていた技術をお金にする手はもう少し考えられてもいいと思います。少なくともうちはそれで商売やっていますし、それで成り立っていますから、皆さん方ができない理由は特にはないのではないかと思います。だとすれば、きっと生き残りなんて簡単です。本当に大きな市場がまだ眠ったままだと思います。そんなふうにお考えいただければ楽なのかなと思います。
もちろんXMLの勉強だとかなんとかというと、勉強ぎらいだときついかもしれませんが、少なくとも生き残っていくための必要な勉強とお考えいただいて、そこはできれば、吸収していただいてご自分のものにしていただければ、結構明るい未来があるのではないかとは思うのですが、そんなふうなところを話しておきたいと思います。
以上、比較的平易にお話をしたつもりでございます。
―了―
|
|
 戻る
戻る to Main
to Main